












{News}{Sci-tech}
2 mins readDataXight Launches protoXell to Unlock Mechanistic Insight from Large-Scale Perturbation Data
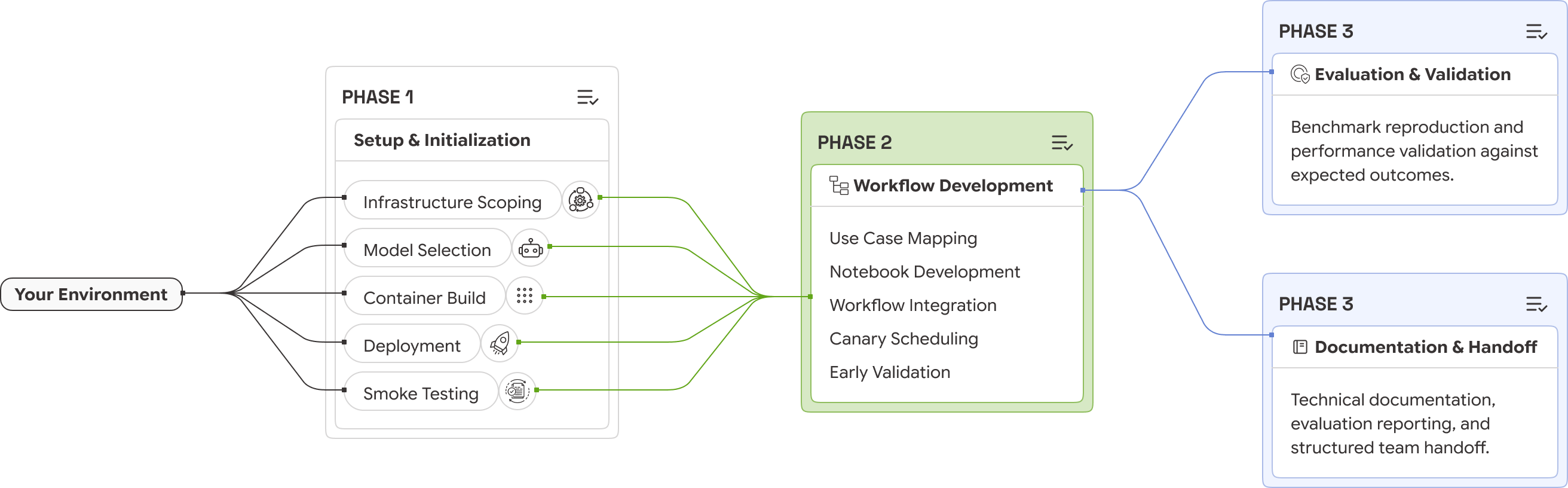
New scientific software enables researchers to explore chemical and genetic perturbations, accelerating target discovery and drug repurposing MOUNTAIN VIEW, CA – May 19, 2026 – Addressing the persistent challenge scientists face in transforming complex biological perturbation data into actionable mechanistic insight, DataXight today announced protoXell, a new scientific software designed to streamline discovery. To learn more about protoXell and explore access options, visit https://dataxight.c


